

.png?width=600&height=2000&name=Historias-12%20(2).png)
El acrónimo "ETL" se utiliza a menudo para referirse a la integración de datos; las actividades necesarias para respaldar la analítica. Estas actividades incluyen:
- Recopilación y extracción de datos
- Carga en un destino
- Transformación en modelos que los analistas puedan usar
El orden preciso en el que se realizan esas actividades puede variar. En este artículo, describiremos dos enfoques conceptuales principales para la integración de datos, ETL y ELT. A su vez, te explicaremos en qué se diferencian y cuál es más conveniente.
¿Qué es ETL?
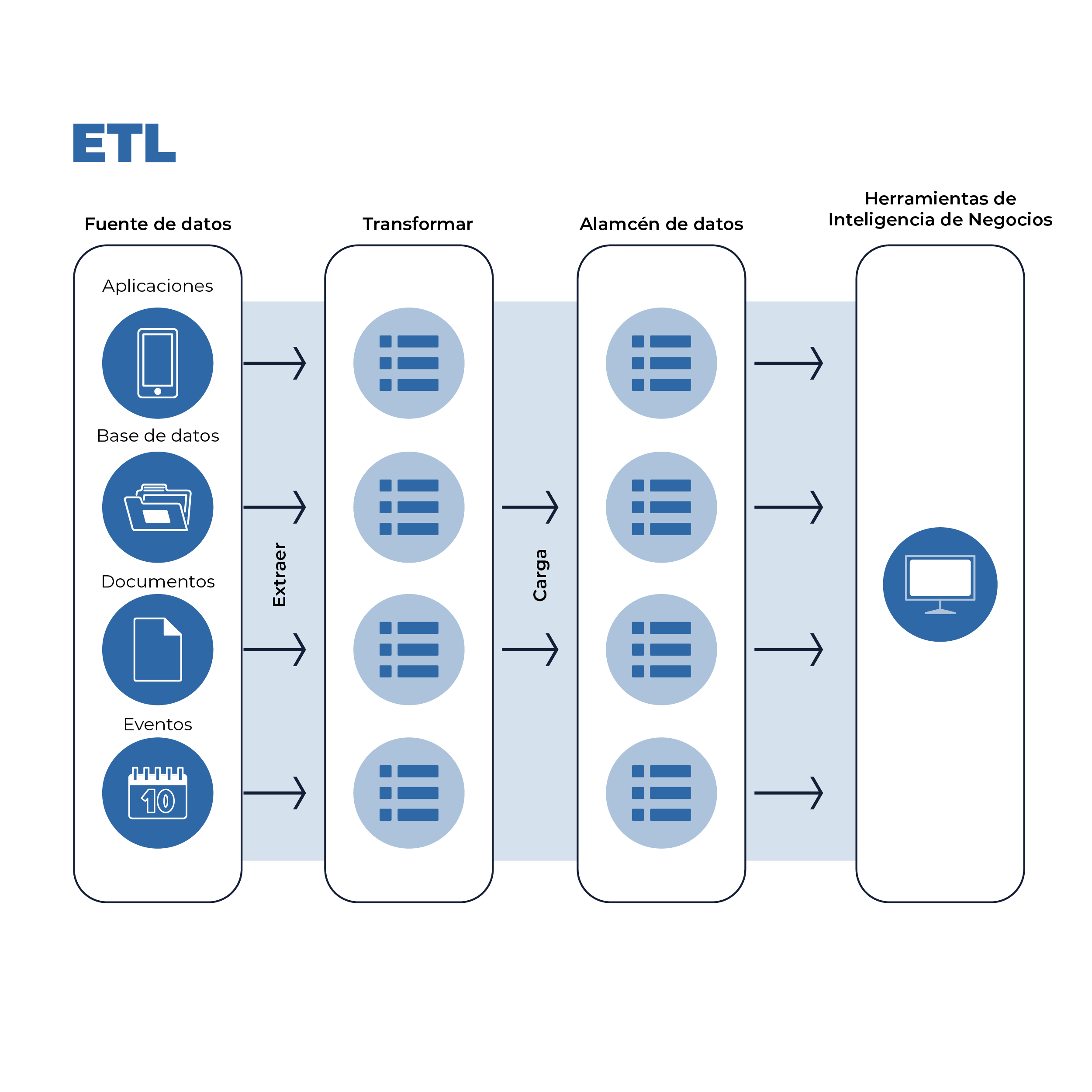
Imagen 1. Características ETL
El enfoque tradicional para la integración de datos, Extraer-Transformar-Cargar (ETL), data de la década de 1970 y es tan omnipresente que "ETL" se usa a menudo indistintamente con la integración de datos. Con ETL, las canalizaciones de datos extraen datos de las fuentes, los transforman en modelos de datos para que los analistas los conviertan en informes y paneles, y luego los cargan en un almacén de datos.
Las transformaciones de datos generalmente agregan o resumen datos, reduciendo su volumen general. Al transformar antes de cargar, ETL limita el volumen de datos almacenados, preservando los recursos de almacenamiento, computación y ancho de banda en todo el flujo de trabajo.
Cuando se diseñó ETL por primera vez en la década de 1970, la mayoría de las organizaciones operaban bajo restricciones tecnológicas muy estrictas. El almacenamiento, la computación y el ancho de banda eran extremadamente escasos.
El flujo de trabajo del proyecto para ETL consta de los siguientes pasos:
- Identificar las fuentes de datos deseadas
- Alcance de las necesidades analíticas exactas que el proyecto debe resolver
- Definir el modelo / esquema de datos que necesitan los analistas y otros usuarios finales.
- Construye la tubería, que consta de funciones de extracción, transformación y carga
- Realizar trabajo de análisis y extraer conocimientos.
Dado que, en ETL, la extracción y la transformación se realizan antes de que los datos se carguen en un destino, están estrechamente acoplados. Además, debido a que las transformaciones están dictadas por las necesidades específicas de los analistas, cada canal de ETL es una solución complicada y personalizada.
La naturaleza personalizada de estas canalizaciones hace que su escalamiento sea muy difícil, en particular al agregar fuentes y modelos de datos.
Hay dos condiciones comunes bajo las cuales se debe repetir este flujo de trabajo:
- Los esquemas ascendentes cambian, invalidando el código utilizado para transformar los datos sin procesar en los modelos de datos deseados. Esto sucede cuando se agregan, eliminan o cambian campos en la fuente.
- Los análisis posteriores deben cambiar, lo que requiere que el código de transformación se reescriba para producir nuevos modelos de datos. Esto suele suceder cuando un analista desea crear un panel o informe que requiere datos en una configuración que aún no existe.
Cualquier organización que mejore constantemente su conocimiento de los datos se encontrará con estas dos condiciones con regularidad.
El estrecho acoplamiento entre extracción y transformación significa que las paradas de transformación también evitan que los datos se carguen en el destino, creando tiempo de inactividad.
Por lo tanto, el uso de ETL para la integración de datos implica los siguientes desafíos:
- Mantenimiento constante: dado que la canalización de datos extrae y transforma datos, en el momento en que cambian los esquemas ascendentes o los modelos de datos descendentes deben cambiarse, la canalización se rompe y, a menudo, se requiere una revisión extensa de la base del código.
- Personalización y complejidad: las canalizaciones de datos no solo extraen datos, sino que realizan transformaciones sofisticadas adaptadas a las necesidades analíticas específicas de los usuarios finales. Esto significa una gran cantidad de código personalizado.
- Intensidad de mano de obra y gastos: debido a que el sistema se ejecuta en una base de código a medida. Requiere un equipo de ingenieros de datos dedicados para construir y mantener.
Estos desafíos son el resultado de la compensación clave hecha bajo ETL, que es conservar los recursos de computación y almacenamiento a expensas del trabajo.
Tendencias tecnológicas hacia la integración de datos en la nube
La intensidad de la mano de obra era aceptable en un momento en que la computación, el almacenamiento y el ancho de banda eran extremadamente escasos y costosos, y el volumen y la variedad de datos eran limitados. ETL es producto de una época con limitaciones tecnológicas muy importantes respecto a lo que impera actualmente.
- El costo del almacenamiento se ha desplomado de casi $ 1 millón a una cuestión de centavos por gigabyte (un factor de 50 millones) en el transcurso de cuatro décadas:
- El costo de la computación se ha reducido en un factor de millones desde la década de 1970
- Y el costo del tránsito de Internet se ha reducido en un factor de miles
Estas tendencias han hecho que ETL sea obsoleto para la mayoría de los propósitos de dos maneras. Primero, la asequibilidad de la computación, el almacenamiento y el ancho de banda de Internet ha llevado al crecimiento explosivo de la nube y los servicios basados en la nube.
A medida que la nube ha crecido, también han aumentado el volumen, la variedad y la complejidad de los datos. Una tubería frágil y personalizada que integra un volumen y una granularidad limitados de datos ya no es suficiente.
En segundo lugar, las tecnologías modernas de integración de datos sufren menos restricciones en el volumen de datos que se almacenarán y en la frecuencia de las consultas realizadas dentro de un almacén.
La asequibilidad de la computación, el almacenamiento y el ancho de banda de Internet ha hecho que sea práctico reordenar el flujo de trabajo de integración de datos. Lo más importante es que las organizaciones ahora pueden permitirse almacenar datos sin transformar en almacenes de datos.
¿Qué es ELT? Una alternativa moderna a ETL
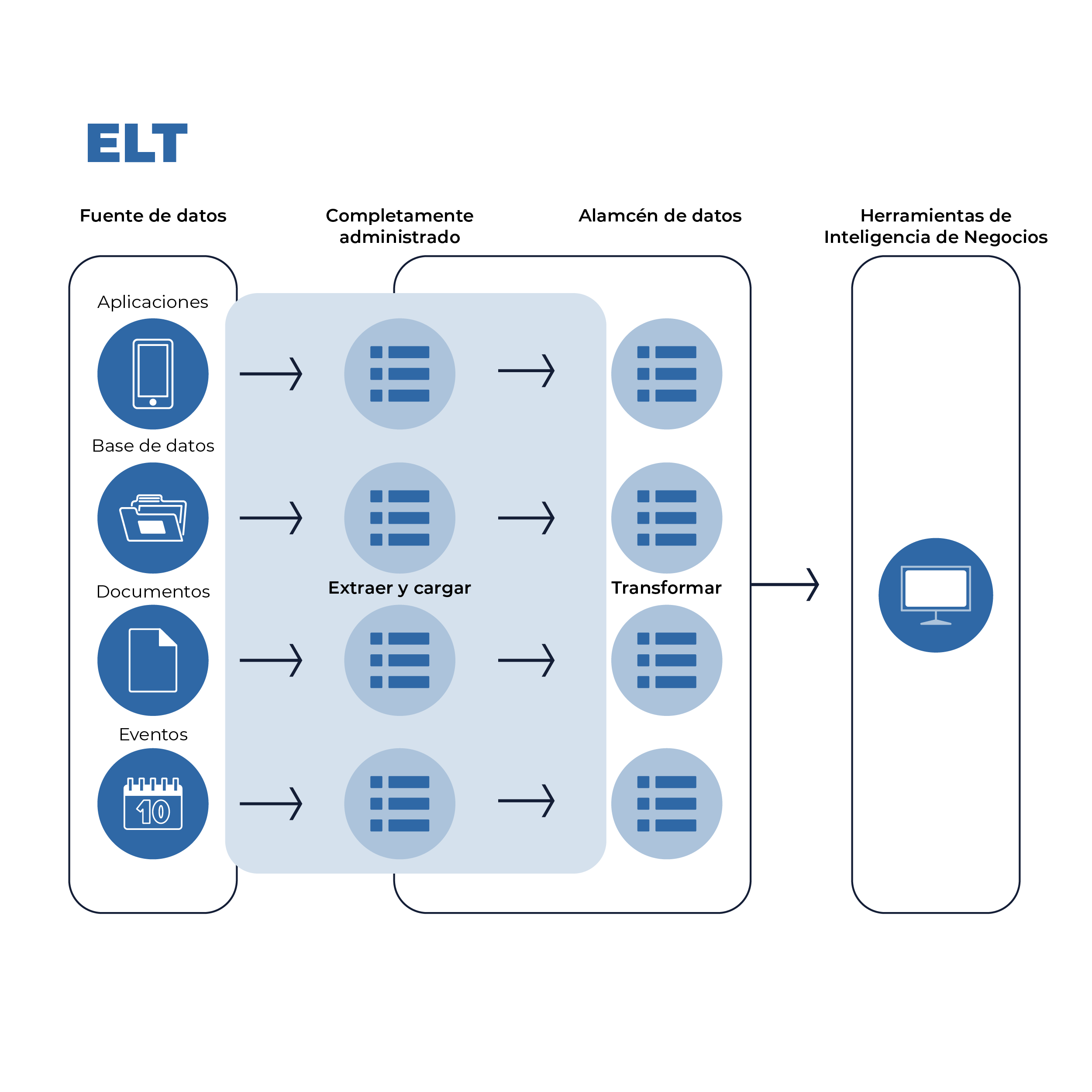
Imagen 2. Características ELT
La capacidad de almacenar datos sin transformar en almacenes de datos permite una nueva arquitectura de integración de datos, Extract-Load-Transform (ELT), en la que el paso de transformación se mueve al final del flujo de trabajo y los datos se cargan inmediatamente en un destino después de la extracción.
Esto evita que los dos estados de falla de ETL (es decir, cambiar los esquemas ascendentes y los modelos de datos descendentes) afecten la extracción y la carga, lo que lleva a un enfoque más simple y robusto para la integración de datos.
A diferencia de ETL, el flujo de trabajo de ELT presenta un ciclo más corto:
- Identificar las fuentes de datos deseadas
- Realizar extracción y carga automatizadas
- Alcance de las necesidades analíticas exactas que el proyecto debe resolver
- Crea modelos de datos construyendo transformaciones
- Realiza un trabajo analítico real y extrae conocimientos
En ELT, la extracción y la carga de datos son independientes de la transformación en virtud de que están en sentido ascendente. Aunque la capa de transformación aún puede fallar a medida que cambian los esquemas ascendentes o los modelos de datos descendentes, estas fallas no evitarán que los datos se carguen en un destino.
En cambio, incluso cuando los analistas reescriben periódicamente las transformaciones, una organización puede continuar extrayendo y cargando datos. Dado que estos datos llegan a su destino con una alteración mínima, sirven como una fuente de verdad completa y actualizada.
Más importante aún, el desacoplamiento de la extracción y la carga de la transformación significa que la salida de la extracción y la carga ya no debe personalizarse. El destino puede llenarse con datos directamente desde la fuente, sin más que una limpieza y normalización ligeras. Combinado con el crecimiento de la nube, esto significa que la extracción y la carga pueden ser:
- Subcontratado a un tercero
- Automatizado
- Escalado hacia arriba y hacia abajo según sea necesario sobre la nube
La extracción y carga automatizadas produce una salida estandarizada, lo que permite que productos derivados, como productos analíticos con plantillas, se produzcan y se coloquen en capas sobre el destino.
Además, dado que las transformaciones se realizan dentro del entorno del almacén de datos, ya no es necesario diseñar transformaciones a través de interfaces de transformación de arrastrar y soltar, escribir transformaciones utilizando lenguajes de secuencias de comandos como Python, o crear orquestaciones complejas entre fuentes de datos dispares.
En cambio, las transformaciones se pueden escribir en SQL, el idioma nativo de la mayoría de los analistas. Esto cambia la integración de datos de una actividad centrada en TI o ingeniero a una que los analistas pueden poseer directa y fácilmente.
Principales diferencias entre ETL y ELT
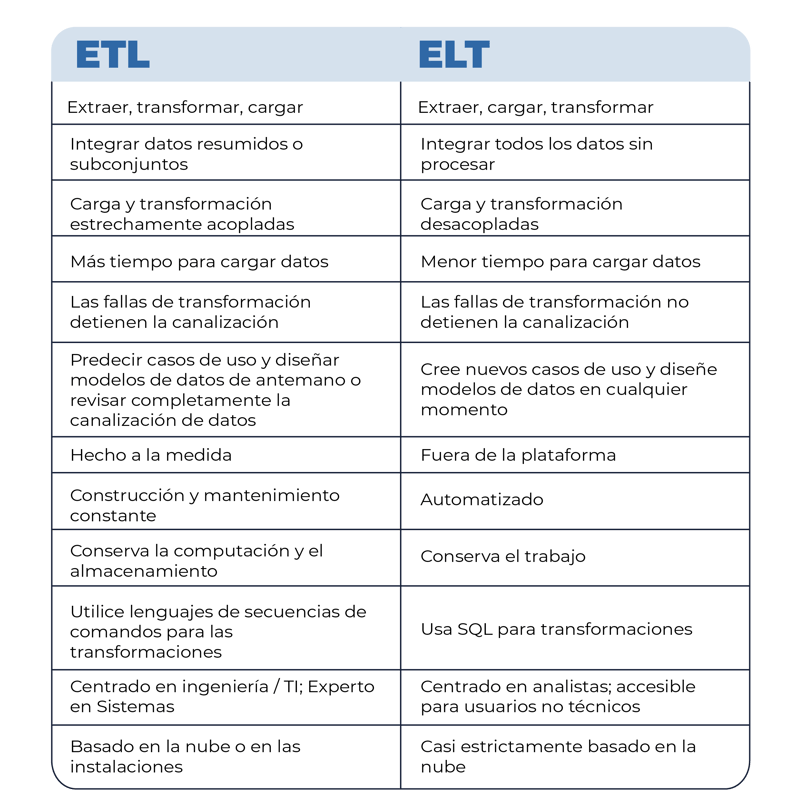
Imagen 3. ETL vs. ELT
Hay algunos casos en los que ETL puede ser preferible a ELT. Estos incluyen específicamente casos en los que:
- Los modelos de datos deseados son bien conocidos y es poco probable que cambien rápidamente. Este es especialmente el caso cuando una organización también crea y mantiene sistemas que generan datos de origen.
- Existen estrictos requisitos de seguridad y cumplimiento normativo con respecto a los datos, y no se pueden almacenar en ningún lugar que pueda verse comprometido.
Estas condiciones tienden a ser características de empresas y organizaciones muy grandes que se especializan en productos de software como servicio. En tales casos, puede tener sentido utilizar ELT para la integración de datos con productos SaaS de terceros mientras se conserva ETL para integrar fuentes de datos patentadas internas.
Conclusión:
Una organización que combina la automatización con ELT está destinada a simplificar drásticamente su flujo de trabajo de integración de datos.
Un flujo de trabajo de integración de datos simplificado actúa como un multiplicador de fuerza para la ingeniería de datos, lo que permite a los ingenieros de datos concentrarse no en construir y mantener tuberías de datos, sino en proyectos más críticos para la misión, como optimizar la infraestructura de datos de una organización o producir modelos predictivos.


Comentarios